Creating AI Applications with PGVector and PostgreSQL: A Hands-On Introduction
23 Oct 2024
7 min read
Share:
In the realm of artificial intelligence, the ability to efficiently store and retrieve high-dimensional data has become increasingly pertinent. As a result, it’s only natural that database systems have evolved to meet these needs. Enter pgvector — a powerful extension for Postgres that brings vector similarity search capabilities to an industry-standard database system.
In this article, we’ll explore how we can leverage pgvector and Postgres together with the OpenAI API in order to create AI-driven applications. Along the way, we’ll briefly explain key concepts such as embeddings and vector similarity search.
Understanding PostgreSQL and pgvector
PostgreSQL, also known as Postgres, is an open-source object-relational database system with over 30 years of active development. Known for reliability, a wide range of features, and performance, Postgres is a popular choice for any application, from small projects to large enterprise software.
pgvector is a Postgres extension that adds vector similarity search capabilities to the database. In AI, vector similarity search is crucial for many applications, including recommendation systems, natural language processing, image recognition, and more. pgvector allows you to both store and query high-dimensional vectors efficiently within your Postgres database.
The Power of Embeddings in AI
Embeddings are at the heart of many modern AI applications. They are vector representations of data that capture semantic meaning and relationships. Embeddings measure how related text strings are, allowing for more nuanced comparisons than simple text matching.
An embedding is essentially just a list (vector) of floating-point numbers. The distance between two vectors measures their relatedness. Small distances suggest high relatedness, while large distances suggest low relatedness. This makes embeddings incredibly useful for tasks like semantic search, recommendation systems, and content-based filtering.
Why Vector Databases Matter
Vector databases, like Postgres with pgvector, offer significant advantages in AI applications:
Efficient Similarity Search: They excel at finding “similar” items, which is often more valuable than exact matches in AI applications.
Handling High-Dimensional Data: They’re optimized for storing and querying high-dimensional vectors produced by machine learning models.
Scalability: Specialized indexing methods allow for quick queries even with millions of vectors.
Semantic Understanding: They enable context-aware searches, understanding the meaning behind queries.
These capabilities make vector databases ideal for various AI applications, including:
- Recommendation systems
- Semantic search engines
- Content-based filtering
- Image and audio similarity search
- Natural language processing tasks
By augmenting Postgres with pgvector, developers can leverage these powerful capabilities while still benefiting from the robustness and extensive feature set of a mature relational database system.
Starting an AI Project with Batteries Included
Batteries Included offers a streamlined approach to working with AI projects, complete with integrated database support. We’ll be using Jupyter Notebooks to run Python code and interact with both the OpenAI API as well as a Postgres database.
Jupyter Notebooks provide an interactive environment where you can write and execute code, visualize data, and document your work all in one place. This makes them ideal for exploratory data analysis, prototyping AI models, and sharing results with others.
Let’s get started!
Step 1: Install the Jupyter Notebook Battery
First, we need to install the Battery that allows us to create Jupyter Notebooks:
- Open the control server and navigate to the
AIsection. - Install the
Jupyter NotebookBattery, granting us the ability to create Notebooks.
Step 2: Create a PostgreSQL Cluster
Next up, we need the actual database we will use together with the Jupyter Notebook. Batteries Included makes this easy:
- Navigate to the
Datastoressection. - Click on
New PostgreSQLto begin creation. - Add or modify a user to be in the
battery-ainamespace. This will store the user credentials in a secret that is accessible by the AI Battery. - Click
Save Postgres Clusterto finalize creation.
Step 3: Set Up the Jupyter Notebook
Lastly, we need to create the Jupyter Notebook itself:
Let’s navigate back to the
AItab.There should be a
Jupyter Notebookssection available now. Click onNew Notebookto begin creation.We’re going to go ahead and add two environment variables:
OPENAI_KEY: We’ll be using OpenAI to generate embeddings, so we need an API key to authenticate.DATABASE_URL: Navigate to theSecrettab, and point this to theDSNsecret created by the Postgres cluster in the previous step.
Click
Save Notebookto finalize creation.
Note: It might take a few moments for the Notebook to finish initializing.
Locally Accessing the Database
For local development or when you want to use your own tools to set up the database with embeddings, you can use the bi CLI tool to get a connection string for your PC:
export DATABASE_URL=$(bi postgres access-info mycluster myusername --localhost)This command retrieves the connection information for your Postgres cluster, which you can then use with e.g. PgAdmin or DBeaver. You can skip this step if you’re only using the Jupyter Notebook or connecting remotely.
Note: The
appdatabase is used by default.
Step 4: Initializing the Jupyter Notebook
Go ahead and open up the Jupyter instance and start a Python 3 Notebook.
Now we’re ready write code. Let’s begin by installing the packages we’ll be using:
!pip install psycopg2-binary
!pip install openai
!pip install pgvectorpsycopg2 is a PostgreSQL adapter for Python, openai is the official Python client for the OpenAI API, and pgvector is needed to interface with the pgvector extension in our Python code.
Now, connect to the database using the DATABASE_URL environment variable:
import psycopg2
import os
conn = psycopg2.connect(os.environ['DATABASE_URL'])
cur = conn.cursor()Step 5: Set Up pgvector and Create the Documents Table
Next, we’ll set up pgvector and create a table to store our documents and their embeddings:
import openai
import numpy as np
import psycopg2
from pgvector.psycopg2 import register_vector
from openai import OpenAI
# Set up OpenAI API
client = OpenAI(api_key=os.environ['OPENAI_KEY'])
# Install pgvector
cur.execute("CREATE EXTENSION IF NOT EXISTS vector;")
conn.commit()
register_vector(conn)
# Create a table to store documents and their embeddings
cur.execute("""
CREATE TABLE IF NOT EXISTS documents (
id SERIAL PRIMARY KEY,
content TEXT,
embedding VECTOR(1536)
);
""")
conn.commit()Step 6: Import Example Dataset and Create Embeddings
Now, let’s create an example dataset and generate some embeddings:
# Sample documents
documents = [
"Foxes are great night-time predators",
"Foxes can make over 40 different sounds",
"Foxes make use of the earth's magnetic field to hunt",
"Baby foxes are unable to see, walk or thermoregulate when they are born",
]
for doc in documents:
# Generate embedding using OpenAI
response = client.embeddings.create(input=doc, model="text-embedding-ada-002")
embedding = response.data[0].embedding
# Insert document + embedding into the database
cur.execute("INSERT INTO documents (content, embedding) VALUES (%s, %s);", (doc, embedding))
conn.commit()Leveraging pgvector
Now that we have our environment set up and data stored, let’s explore how we can use pgvector in our AI applications.
- Indexing: Let’s start by creating an index on the embedding column to speed up similarity searches:
cur.execute("CREATE INDEX ON documents USING ivfflat (embedding vector_l2_ops);")
conn.commit()- Similarity Search: When a query comes in, let’s generate an embedding for the query and use pgvector’s similarity search capabilities to find the nearest row in your database:
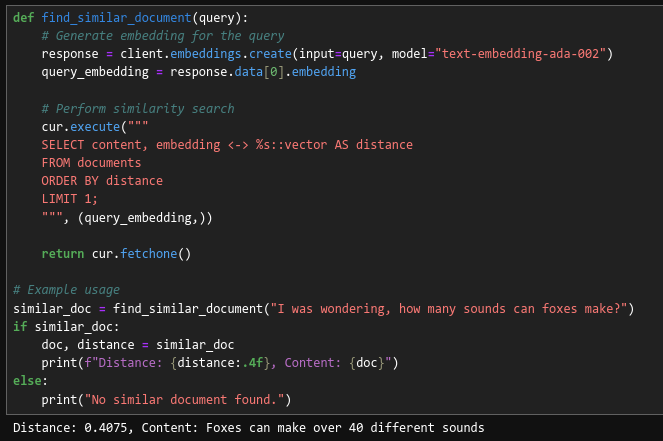
def find_similar_document(query):
# Generate embedding for the query
response = client.embeddings.create(input=query, model="text-embedding-ada-002")
query_embedding = response.data[0].embedding
# Perform similarity search
cur.execute("""
SELECT content, embedding <-> %s::vector AS distance
FROM documents
ORDER BY distance
LIMIT 1;
""", (query_embedding,))
return cur.fetchone()
# Example usage
similar_doc = find_similar_document("I was wondering, how many sounds can foxes make?")
if similar_doc:
doc, distance = similar_doc
print(f"Distance: {distance:.4f}, Content: {doc}")
else:
print("No similar document found.")This function will return the most similar document to the given query, along with its distance score.
For example, performing a vector similarity search with the string:
I was wondering, how many sounds can foxes make?
Yields:
Distance: 0.4075, Content: Foxes can make over 40 different sounds
Wrapping Up
And that’s really it! As your projects grow, you can effortlessly manage millions of vectors while maintaining swift query times, thanks to Postgres and pgvector’s efficient indexing. Whether you’re developing a cutting-edge recommendation system or diving into novel AI applications, this combination offers a flexible and powerful platform to realize your ideas.